Data Model
Basic Data Operations: selection, projection, union and join
Sturctre
Person{
firstName: string,
lastName: string,
DOB: date
}
Relational Data Model
Represented as Table; relational tuple as row in the table
Atomic: represent one unit of information and cannot be degraded further
Header tells the constaints:
ID: Int Primary Key | Fname: string Not null
Foreign Key: that refer to the primary key in the parent table; and foreign key is not unique
Union Operation: UNION removes duplicate records (where all columns in the results are the same), UNION ALL does not.
Structured vs. Semi-structured (as tree-structured)
Web pages: html, XML (generalization of HTML where the beginning and end markers within the angular brackets can be any string), json
XML allows the querying of both schema and data
json: key-value pair in tuple in square brackets (indicate arrays
Treat semi-structured data as tree -- allow nagivation of access to data
Vector Space Model
Text Data
Decument vector model as "vector model"
TF-IDF: term frequency and inverse document frequency
Use log2 is more of a convention in many areas of Computer Science; IDF acts as a penalty for terms that are too widely used.
Term Frequency
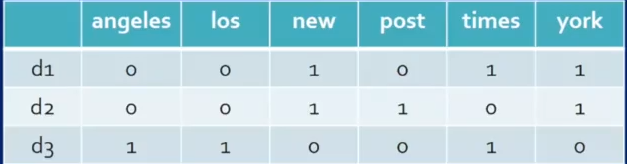
TF-IDF Matrix

Length of d1 = sqrt(0.584^2 * 3) = 1.011
Query Vector
If the query term is "new new york", then the query vector would be:
[0 0 (2/2)0.584 0 0 (1/2)0.584] corresponding to
[angeles los new post times york] while each factor is $\frac{#\ of\ occurrence}{max_i{frequency}}$
A similarity function between 2 vectors is a measure of how far they are apart: Use Cosine
Query Term Weighting
Every query term may optionally be associated with a weighting term
Q=York times^2 post^5; so that wt(York) = 1/(1+5+2)=1/8; wt(times) = 2/8 = 0.25 and wt(post) = 5/8 = 0.625.
Multiply the query vector with these weights.
Graph Data Model
Connected Network, Anolnamous Network, Connected Components, Shortest Path
Other Data Models
- array as a Data Model; Arrays of Vectors (get back the whole vector like images data)
Data Format vs. Data Model
For example, csv is a data format but if plotted as a graph, then it 's a data model.
Data Stream
Managing and processing data in motion is a typical capability of streaming data system.
Dynamic Steering is often a part of streaming data management and processing -- dynamically changing the next steps or direction of an application through a continuous computational process using streaming. (E.g. self-driving car)
Data-at-rest vs. Data-in-motion
- Mostly static data from one or more sources; collected prior to analysis; batch processing
- Analyzed as it is generated (sensor data from self-driving car); stream processing
Property of Steaming data processing: Unbounded size, but finite time and space
The modelling and managemnet of streaming data should enable computations on one data element or a small window of group of recent data elements; No iteraction with the data source.
Lambda Architecture
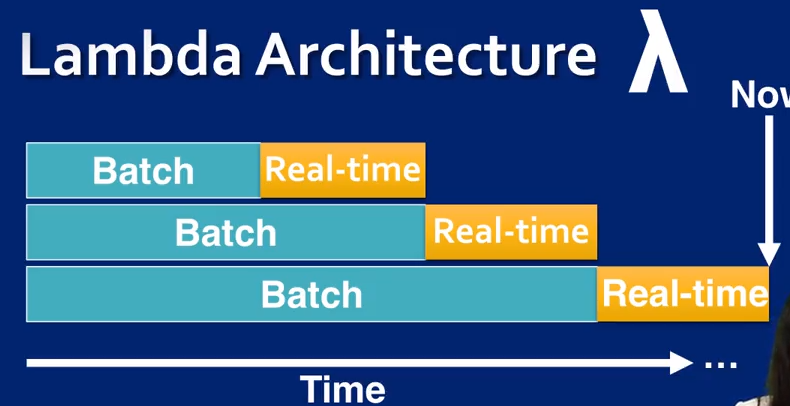
Streaming wheel over the real-time data is managed and kept until those data elements are pushed into a batch system and become available to access as batch data.
Big Data Challenge: Scalability, data replication, durability and fault tolerance. 2 main challenges -- avoid data loss and enable real time analytical tasks.
Streaming data changes can be periodic (evenings, weekends) and sporadic (major events, breaking news)
What's Streaming? Utilizing real-time data to compute and change the state of an application continuously,
Steaming data must be handled differently than static data
Size --> unbounded
Size and Frequency --> Unpredictable
Processing --> Fast and Simple
Properties of Working with Streaming Data
- Does not ping the source interactively for a response upon receiving the data
- Small time windows for working with data
- Data manipulation is near real time
- Independent computations that do not rely on previous or future data
Data Lake as a massive storage depository
load data from source --> store raw data --> add data model (sturcture) on read
Enable batch processing of streaming data
Schema on write vs schema on read
Organize data streams, data lakes and data warehourses on a spectrum of big data management and storage
In a Traditional Data Warehouse: schema-on-write -- transform and structure before load; any application using the data needs to know the format in order to retrieve and use the data.
Data Lake: schema-on-read -- data is stored as raw data until it it read by an application where the application assigns structure. all data is stored for a potentially unkonwn use at a later time; object storage.
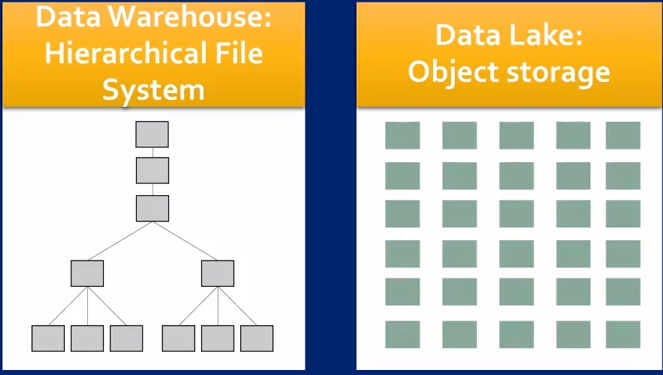

Data Lake Summary
- A big data storage architecture
- collects all data for current and future analysis
- transforms data format only when needed
- supports all types of big data users
- infrastructure componenets which evolve over time based on application-specific needs (perhaps most important)
DBMS
Advantages
- Declarative query languages
- Data Independence
- Efficient access through optimization
- Data Integrity and security
ACID properties of transaction (buying tickets): Atomicity, consistency, isolation and durability
Atomicity: all of the changes that we need to do for these promotions must happen altogether, as a single unit.
Consistency: data must be valid according to all defined rules including constraints
Durability: once transaction commited, it'll remain so no matter power loss.
Concurrency: Many users can simultaneously access data without conflict, transaction must happen as if they are done as series
Traditional DBMS handle big data through parallel and distributed database system
Distributed DBMS: Data is stored across several sites, each site managed by a DBMS capable of running independenly!
MapReduce-stype systems: complex data processing over a cluster of machines; number of machines can go up to thousand
Mixed Solutions: DBMS on HDFS; Relational operations in MapReduce Systems like Spark; Streaming input to DBMS
BDMS Big data management system
Desired Characteristics:
- A flexible, semistructured data model (schema fist to schema never)
- Support for today's common "big data types" (texture, temporal, spatial data values)
- A full query language (expectedly at least the power of SQL)
- An efficient parallel query runtime
- Wide range of query sizes
- Continuous data ingestion (stream ingesting)
- Scale gracefully to manage and query large volumes of data (use large clusters)
ACID properties hard to maintain in a BDMS
BASE relaxes ACID: BA as basic availability; S as soft state (state of the system is very likely to change over time); E as eventual consistency (system will eventually become consistent once it stop receiving input)
CAP Thm A distributed computer system (the network is partitioned, nodes in different parts of the network have different content) cannot simultaneously achieve
Consistency: all nodes see the same data at any time
Availability: every request receive a reponse about sucess/fail
Partition Tolearace: system continue to operate despite arbitrary partitioning due to network failures
at the same time.
Most of the big data systems available today will adhere BASE properties, although several modern system do offer stricter ACID properties or at least several of them.
Redis: an enhanced key-value store (in memory data structure store for fast processing); support stirngs, hashes, lists, sets, sorted sets; used by Twitter
Look-up Problem:
- (key:string, value:string). Redis allows binary as string and have a size of upto 512 MB, use the image itself as the key.
- Keys may have internal structure and expiry, such as user.commercial.entertainment and user.commercial.entertainment.movie-industry
- (key: string, value: list): userID:[ tweetID1, tweetID2, ...] and ziplists (used by Redis) to compress lists in memory without changing the content --> significant reduction in memory use
- (key:string, value: attribute-value pairs): Redis hashes
- Redis scalabilty: Range partitioning (e.g. user record number divided as bins and goes to different); Hash partitioning (H-functino{"key string"} %10 = 2, so the record goes to machine 2)
- Redis replication: Master-Slave mode replication (clients write to master, master replicates to slaves; clients read from the slaves to scale-up read performance; slaves are mostly consistent)
Aerospike: a distributed NoSQL database and key value store for web-scale applications
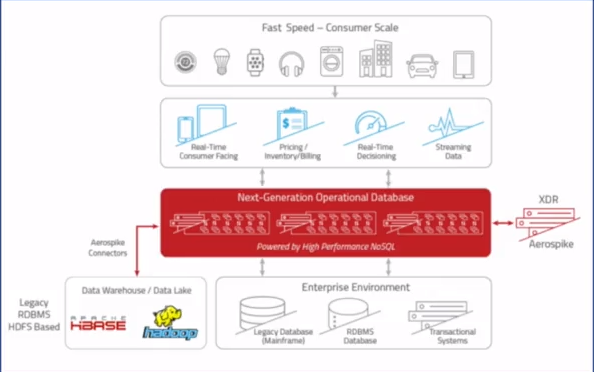
- I/O optimized for SSD storage
- Data Types: standard scalar, lists, maps (like hash table) , geospatial, large objects
- KV store operations allows for geospatial queries like point-in-polygon, restaurant within 3 miles
- AQL: SQL-like language (SELECT name, age FROM users.profiles)
- Aerospike ensures ACID guarantees (Consistency -- all copies of data items are in sync )
MongoDB:dominant store for JSON stype semi-structured data
AsterixDB:provides ACID guarantees

- type as open meaning actual data can have more attributes than specified in the schema here.
- geo: point? means this area is optional
- access external data (rea-time data from files in a directory path)

Solr: for large-scale text data searching
Basic challengegs with text: defining a match (capitalizatino, structural punctuations, nominal variations; synonyms; abbreviations; initialism )

- Engine on Lucene, as an inverted index (Vocabulary as all terms in a collection of documents and Occurrence for each term in the collection -- List of doc ID [position of occurrence])
- Functionality: Enterprise Search Platform; Inverted Index; Faceted Search and Term Highlighting)
- Tokenizer (as filters)

Vertica -- A columnar DBMS
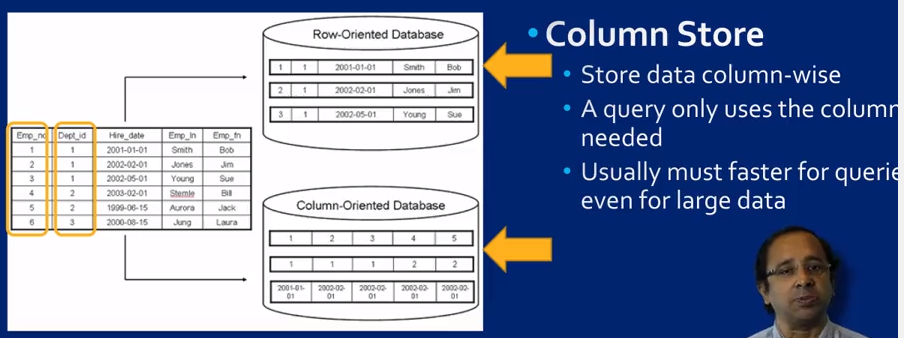
Space Efficiency -- column stores keep columns in sorted order (don't have to store the contigency values); Run-length encoding (1/1/2007 - 16 records)
Frame-of-reference encoding (fix a number and only record the difference)
Column-Groups: frequently co-accessed columns bahave as mini row-stores within the column store
Update Performance Slower: internal conversion from row-representation to column representation and then compress. (lowness can be perceptible for large uploads or updates)
Enhanced Suite of Analytical Operations allows for many more statistical functions than in classical DBMS; analytical computations happens inside the database instead of in an external application

Vertica and Distributed R Uses master node (schedules tasks and sends code) and worker nodes (maintain data partitions (not necessarily equal partition) and compute); uses a data structure called dArray or distributed array

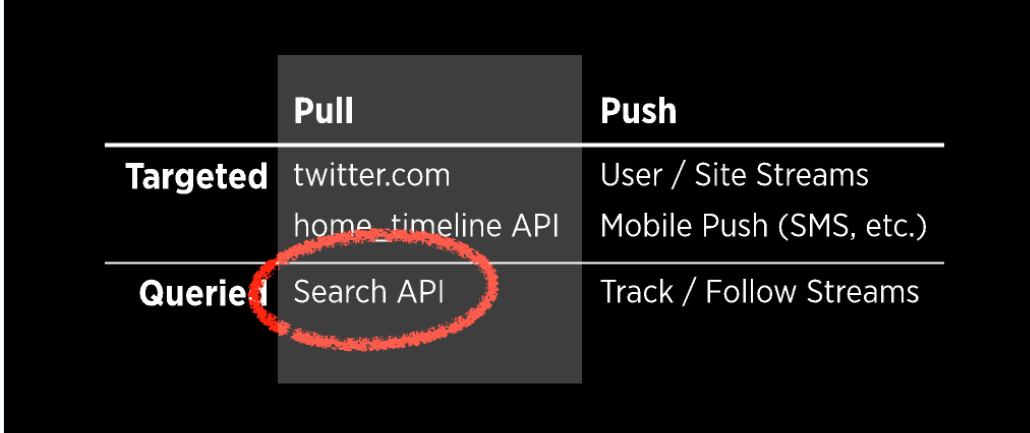
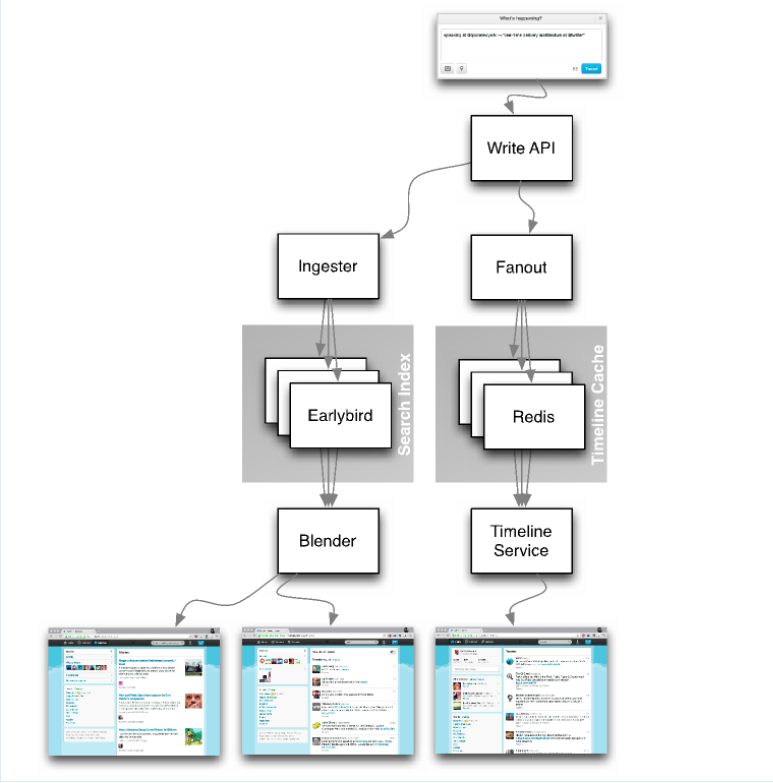
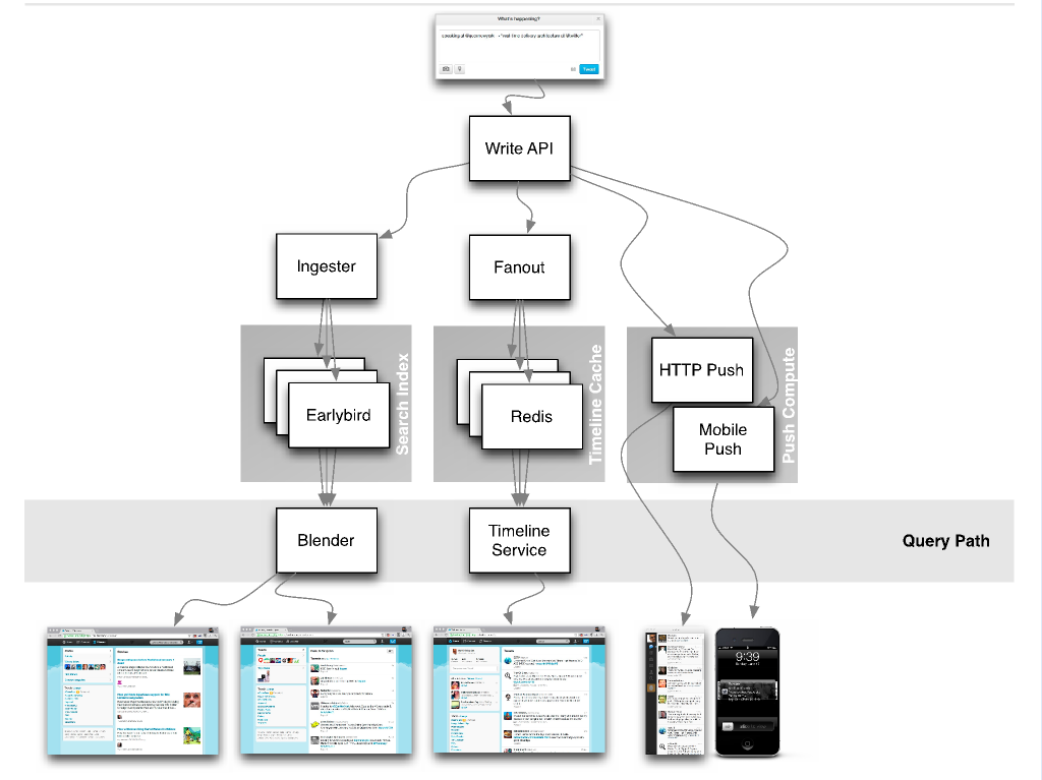
Twitter Redis
Real-Time Delivery Architecture at Twitter